The web application called “Poetry Assessor” has had a second wave of attention since going back online recently. In this post I want to show why Poetry Assessor doesn’t assess poetry, and to make a broader point about the “Humanities” in “Digital Humanities”: that bad disciplinary training makes for bad interdisciplinary work. It’s a longish post because there is much to object to, and the stakes are higher than they might seem, as I discuss near the end.
 The website (http://poetry-assessor.com/poetry/) asks you to enter a bit of poetry into a box, to which it then assigns a score based on a scale from “amateur” to “professional.” As far as I can tell, few people in social media poetry circles take the results very seriously. The two main uses seem to be a) ironic self-evaluation (see here and here, from Don Share’s Facebook comments); and b) testing canonical examples against random text in the hopes that some obviously non-poetic text will trump, say, T. S. Eliot (see here and here) which might say something about Eliot, or the algorithm, or the training set, depending on your point of view.
The website (http://poetry-assessor.com/poetry/) asks you to enter a bit of poetry into a box, to which it then assigns a score based on a scale from “amateur” to “professional.” As far as I can tell, few people in social media poetry circles take the results very seriously. The two main uses seem to be a) ironic self-evaluation (see here and here, from Don Share’s Facebook comments); and b) testing canonical examples against random text in the hopes that some obviously non-poetic text will trump, say, T. S. Eliot (see here and here) which might say something about Eliot, or the algorithm, or the training set, depending on your point of view.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
That is, no one seems to be taking this particularly seriously. But Poetry Assessor takes itself seriously: two academic articles underlie this work. And the Assessor promotes itself on Twitter as a credible revision tool (see here). In one of his articles the author suggests that his method might be of use to a “publisher who needs a quick way of sorting through voluminous submissions.” Were that ever to be implemented, Poetry Assessor would become a valuable tool indeed! [note: at least one editor is listening…]
{kind=link}
The “amateur-professional” score is determined algorithmically, based on
a training set of contemporary American poetry: 100 poems from a published anthology (Contemporary American Poetry, 2006) and 100 from on online database of amateur poetry (www.amateurwriting.com). The method, described in M. Dalvean’s paper “Ranking contemporary American Poems” (Literary and Linguistic Computing, 2013a) involves assessing the most significant linguistic variables in predicting which corpus a training poem belongs to, and then measuring the input poem according to these variables. A second paper, “Ranking Canonical English Poems” (2013b) is set to be published in LLC in the near future.
The variables Dalvean found to be most predictive in the 2013a paper include the incidence of words indicating affect (“love,” “hate,”), of articles (“the”, “a”), numbers, and tense. Dalvean writes that, according to the learning corpora: “professional poems tend to use more concrete language. They use demonstrative language, as indicated by the use of articles…professional poets use words that are somewhat unusual but not necessarily complex. Professional poems have fewer words denoting affect but more words denoting number. Professional poems also refer less to the present and to time in general than amateur poems.” (p.11)
In an article of my own on “Method as Tautology in the Digital Humanities,” also published in Literary and Linguistic Computing (2013), I offered the view that Dalvean 2013a is:
misinformed (or not informed) about the disciplinary concerns of poetry criticism. The ostensible subject of the research (contemporary American poems) is a mere test case for a digital method. If it is of any use at all … this work will be of use to researchers in machine learning and automatic classification, not in literature.
There are lots of reasons why I would argue that Poetry Assessor tells us nothing about poetry, but mainly they stem from the fact that “amateur” and “professional” are not critical or evaluative categories in any of the literary criticism I’ve read, not in the sense employed here (though you sometimes see it pop up to differentiate the pure lover of poetry from the careerist). While the two computational linguistics studies Dalvean cites employ the same distinction, as far as I know it has no status whatsoever in the history of writing about literature.
Neither is the fact of contemporary publication (let alone anthologization) very convincing as a proxy for other critical and/or evaluative categories, especially when we’re talking about contemporary poems, as the prominence of such poets as Emily Dickinson and Gerard Manley Hopkins in the anthologies of later days shows quite clearly.
One reason for this is that what we might call broad cultural taste in poetic style (i.e., what gets published today, what gets anthologized tomorrow) changes over time, and the time over which it changes can be short. Moreover, changes in taste are by definition prompted by innovations of style. Eliot’s poems aren’t like Georgian poems. They were published to great acclaim, but this was not despite their difference from the stylistic norm. It was because of it.
I think this basic point would be obvious to anyone with any familiarity with poetry, criticism, literary study, etc., but Dalvean doesn’t see things that way. The most generous characterization of his position might be that, despite changes in style, there are still certain features common to all “successful” poetry–“the basic skills associated with writing poetry,” he calls these–which underlie all these superficial changes. But this is no more credible a position: even if true statistically, leads us nowhere as critics, readers, and writers. Unlike the algorithm, we are typically more interested in the things that make great poems different from each other than what makes them similar. And we aren’t much interested in bad poems at all.
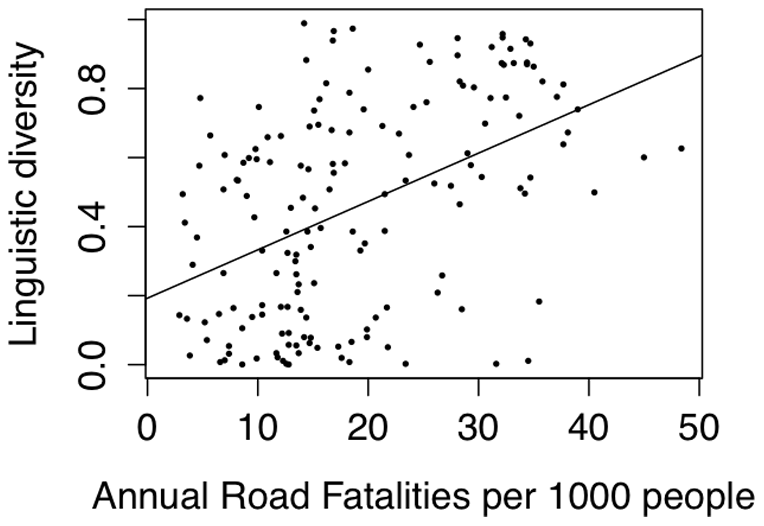
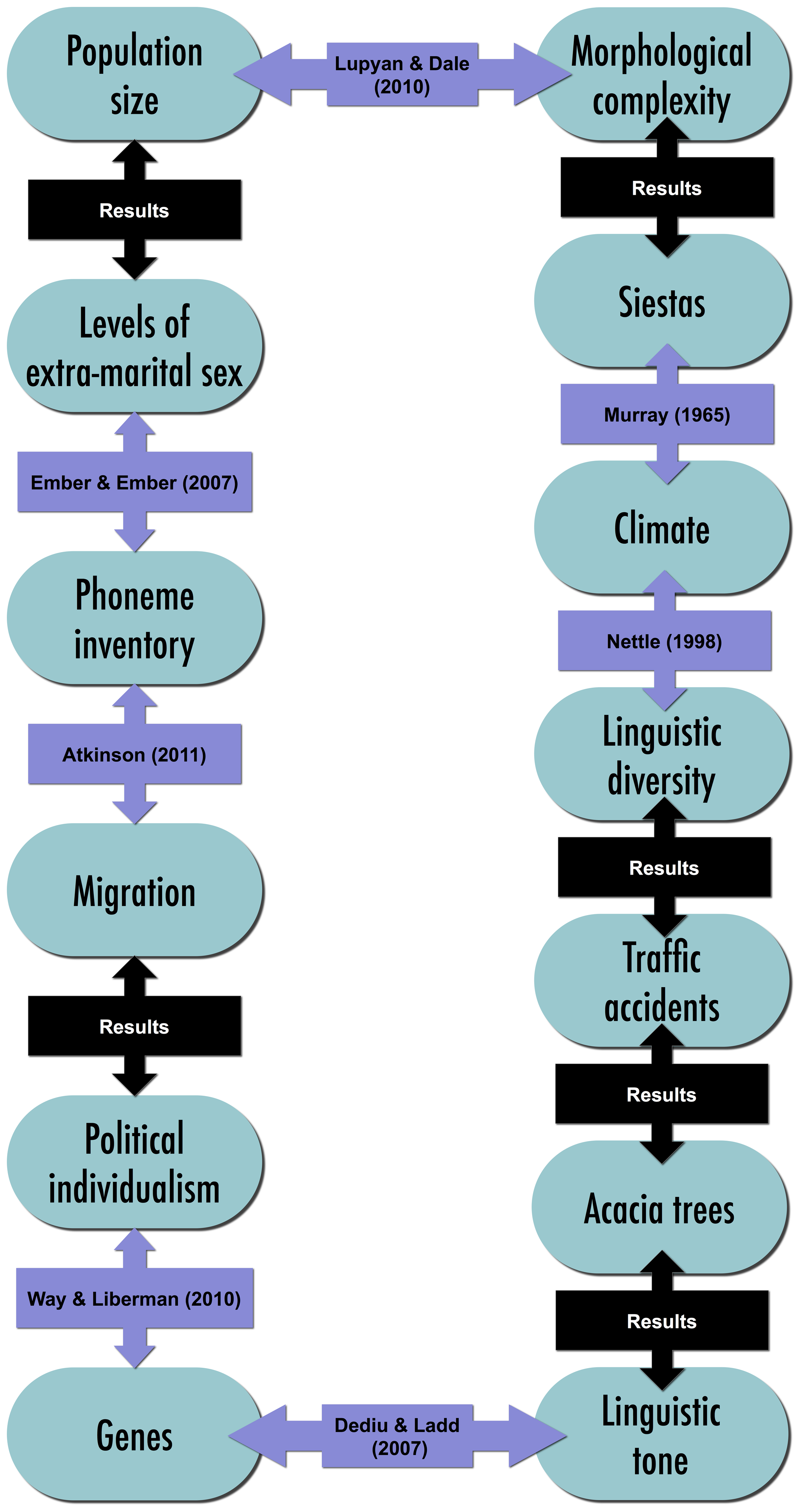
I say “even if true statistically.” Let us be clear that the algorithm Dalvean is applying is detecting correlations among a set of features in a training set of poems. Whether these correlations hold more broadly we don’t know. But more importantly, we also have no evidence that these correlations should be taken as causative, which is what is implied when the Assessor suggests you revise your crappy amateur poem to get a higher professionalism score. This is a big problem with big data: correlations are everywhere, and most of them mean nothing. No time to elaborate on this now, but see here, here, here, and especially here, with this chart showing a strong correlation between linguistic diversity an road fatalities, and this wonderful illustration of a correlation chain.
{kind=link}
{kind=link}
Even so, as critics, scholars, Digital Humanists, whatever, we might still keep Dalvean’s method kicking around if it told us something of value about poetry. Something we could discuss or argue over, or something that would change or affect our understanding of poetry, or poetic taste, or poetic movements, or whatever.
The criteria for establishing what might count as such a something I think would have to come out of some subdiscipline of literary studies. These are the various methods we have developed over decades and centuries to make sense of this type of cultural production. They are not objective (however much they might appeal to objectivity), but neither are they arbitrary. These criteria would not be unsusceptible to modification by the new information about poems or poetry, but they would have some fundamental role in guiding the interpretation of the data. They would not impose a particular type of conclusion, but rather establish a provisional set of epistemological frames and of critical values.
Dalvean understands that “to extend our understanding of poetics in general” would indeed be a relevant scholarly use for his method (in addition to getting your poem published by the guy who runs Poetry Assessor on submissions). Both of his articles include discussions of results which try to locate these within the traditional disciplinary concerns of literary studies. Unfortunately he misunderstands almost all of these concerns.
Let’s look closely at a few of these attempts, to understand why they contribute nothing to the field, serving instead as literarese window-dressing. [If you already believe this and aren’t interested in going through point-by-point, skip to the last part of my discussion, here]
The 2013a article found that (1) imagery and concrete language (proxy: prevalence of articles, numbers) is typical of professional poetry, while (2) emotion (proxy: prevalence of words on list of “affect” vocabulary) is more typical of amateur poetry.
1. Claim one is contextualized by quoting Keats on his Lamia: “I am certain there is that sort of fire in it that must take hold of people some way; give them either pleasant or unpleasant sensation — what they want is a sensation of some sort.” Thus, Dalvean writes, “the finding…that concreteness is a marker of professionalism has some backing in literary circles.”
I’ll ignore Dalvean’s own warning that his training set is American contemporary poems, not English poems of c.1820, though this seems to me a glaring contradiction. [No doubt the caveat would be invoked to explain Lamia‘s score of 0.4, barely professional, on Poetry Assessor.] The bigger problem is that the linkage from articles/numbers to demonstrative language to concrete language to imagery relies on little more than assumption and assertion. To retrace this, imagery is not equivalent to concrete language [“the mouse ran up the clock” is concrete, but it is an example of bare narrative, not imagery]. In turn, even if the use of articles might signal a demonstrative statement, concreteness is not to be identified with demonstrativeness [“glazed with rain water” is just as concrete as “glazed with the rain water”; “beside white chickens” is just as concrete as “beside the white chickens”]. Are all these categories correlated down the chain? Perhaps, but there’s no evidence to that effect here. To conclude that articles and numbers can be a proxy for imagery in poetry is a stretch, to say the least.
This doesn’t begin to address what Keats was actually talking about in his letter about Lamia. But it’s not merely “imagery.” And it’s certainly not demonstrative articles.
2 The claim about affect is even more tortured. Noting that professional poems use less affect words than amateur ones, Dalvean cites Wordsworth on powerful feelings, Collingwood (!) on artistic emotion, and Furman (!!) on poetry as “emotional microchip,” before finding in Eliot the concept of the “objective correlative,” which he understands as a way of expressing affect without using affect words.
Dalvean is actually on to something here, but it has nothing to do with affect, or the “objective correlative,” which had its moment as a critical category, I’ll admit, but which can’t really be said to have determined the expression of American poetic feeling since at least the mid-century. The real answer is that word-level topic modelling is really bad at figuring out what poems are about. That’s because poems deal in extensive, connotative, symbolic, and metaphorical language, and computers don’t know how to understand these kinds of utterance. That’s not because they miss the connotative aspect, though they often do. It’s because they can’t handle the simultaneity of the denotation and the connotation, the literal and the extensive.
The article ends by considering how the new data will impact literary theory, with a series of stunning characterizations and conclusions:
3 “Marxist interpretations of literature are based on considering the material conditions in which they were formed. Thus, we might expect that those who had not achieved eminence … would use work terms differently than the established poets as their material and cultural outlooks may be coloured by their experiences. In fact, there is no such difference.”
The premise is ludicrous, but see above on topic modelling.
4 “Feminist literary criticism, which, according to one of its manifestations, holds that there is a uniquely male perspective and that this is what needs to be emulated by men and women if they wish to succeed in an androcentric world. This androcentrism is not supported.” [because the gender variable measuring how ‘gendered’ words are is no higher or lower in the professional set].
Oh boy. Words work together in poems. My guess is that “Feminist literary criticism” is more interested in the treatment of those gendered terms within broader constellations of thought, rather than their prevalence.
5 “…the postmodernist holds that there is no difference in terms of literary merit between the cannon of great literature and less lauded text such as advertising copy…There is little evidence of such confusion in the analysis of the difference between professional and amateur poems.” [because the method objectively classifies these categories with an accuracy of 84.5%].
Clearly this begs the question, but I guess the point is that the algorithm has achieved a certain accuracy measure. Let’s remember that not all correlations mean something. But, beyond this, postmodernist or not, to test the claim I would want to see how much advertising copy or other “less lauded text” I could get into the “professional” column using Poetry Assessor – such as, perhaps, the description of Poetry Assessor on poetryassessor.com, which assesses itself at a healthy 3.7, (I get 3.9 – must have copied more or less of the text) a fair bit better than Gary Snyder’s “Hay for the Horses,” which scores 3.2.
If the claim is that the Assessor not only supports the idea of relative objective literary merit in text, but also can measure this (with 84.5% accuracy) then it should do better at identifying non-literary genres. Inputting the first 10 paragraphs of the Wikipedia article on advertising, I find that all but 1 paragraph score above the bar, with one scoring a super-professional 9.2 (the only amateur wiki paragraph poem was just a mildly amateurish -0.9). If anything, this would appear to support the postmodernist position as described by Dalvean. But, you know, it doesn’t.
So there you have it–we finally have an objective way of assessing 2.5 millennia of literary criticism and a couple centuries of theory, and a time-saving tool for the booming future of poetry publication. All it took was the right measures, which luckily computers were able to find for us once we assembled enough meta-textual information. What a relief: we’ve been waiting to “see the object as itself it really is” for at least 150 years.
Dalvean’s follow-up article is “Ranking Canonical English Poems”, which considers 500 linguistic variables in “85 canonical English poems and a matched control group of obscure poems.” The dates of publication range from the early 1500s to the 1920s. You may want to know that Blake’s “A Poison Tree” ranks highest according to the classifier.
In this article, the “amateur/professional” spectrum is left aside in favour of a new construct, a continuum between “qualities related to the use of language (literary appeal) and qualities related to the popularity of the theme, the author and the cultural associations (popular appeal).” No basis is given for this new polarity – it is merely a hypothesis, that poems are anthologized because of a balance between their linguistic aspects and their broader cultural aspects.
But in another bout of question begging, the hypothesis is assumed, and used to excuse the apparently flawed results of the method. Dalvean observes that his classifier has ranked below the bar many poems that are “stalwarts of the canon” such as “Keats’s ‘Ode to a Nightingale’, ‘To Autumn’, and ‘Ode to a Grecian Urn’ [sic] …”. Odd indeed. Odder still are the poems in the highly anthologized group that rank near the bottom of the combined set: Tennyson’s “Ulysses,” Milton’s “On his Blindness” and the aforementioned poem bloody on a Grecian urn. A problem with the classifier? No, just mark it down to “popular appeal” skewing the results of these literarily unappealing works–pesky culture, messing up our algorithms. So the real point of the classifier is not to identify the qualities of highly anthologized poems, but rather to “distil the literary appeal from the popular appeal.”
This makes no sense, of course, and is wholly unsubstantiated. Firstly, since nothing non-linguistic is being measured by the algorithm, there is no way to tell what non-linguistic aspects might be affecting the poem’s rank. Second, this is dancer and dance territory–it is hard to understand how exactly you would talk about the popular appeal of a poem without reference to its language, or how you could avoid considerations of cultural taste when discussing literary aspects. Literary scholars have known this for some time.
Things get predictably worse as Dalvean tries to make sense of the results of this nonsensical model. The key passages from the discussion of results:
The most important variable in the classifier is Harv_Knowl, which … consists of words pertaining to knowledge and cognition. … The implication is that introspection, or even the examination of the internal state of the mind, is not what poets rely on for their efficacy.
The second most important variable is … words such as “and” and “also”. [There follows a chain of correlations and transferences linking inclusive words to cognitive simplicity and cognitive simplicity to naivete. See again the chart of spurious correlations. Then:] Why would naivety be associated with being a HAP [Highly Anthologized Poem]? My contention here is that readers are aware when someone is trying to “sell” an idea to them rather than engage them in the art.
The third most important variable … is that those poems that use standard everyday words are more likely to be HAPs.
The fourth most important variable is … a measure of the dominance represented by words perceived by male subjects…. The idea that words that inspire a reader to feel a male sense of being “in control” are associated with HAPs indicates that it is important that a reader feel that the poem is creating a sense of order out of chaos.
.
Near the end of the piece, Dalvean addresses the brief critique of his earlier essay that I made in “Method as Tautology”. He writes:
A recent criticism of the techniques used in Dalvean (2013) and in the current paper is that such methods are not informed by the disciplinary concerns of poetry criticism and that the techniques used are “…mere test csase[s] for a digital method” (Williams, In press:14). These statements miss the point: the object of Dalvean (2013) is to explore the empirical question of what distinguishes “amateur” poems from professional poems while the object of the current paper is to determine the empirical question of what the difference is between poems that survive to enter the canon and those that don’t. If the “disciplinary concerns of poetry criticism” could be of use here then we might expect that the descriptive commentary of critics over the last 2000 years, including recent attempts aided with digital search methods, might have been able to determine the answers to these questions. In fact, they have not.
In a sense we agree about this last point, except that I think it supports my critique of Dalvean 2013a, rather than rebutting it. The object of both articles have indeed been to explore the empirical question of what distinguishes amateur and professional poems, canonical and non-canonical ones. Only, A) These are spurious categories; B) These are not questions of interest to Humanities scholarship, nor do their answers contribute to questions of interest; and C) Since the concerns of this scholarship are rejected by the author, there is no basis for assessing the relevance of the correlations presented in either article. The attempts at showing such relevance to criticism and theory are, frankly, embarrassing.
Is Dalvean an easy target? Maybe, but I think it’s important to defend the place of the Humanities disciplines and their concerns in the interdisciplinary space that calls itself the Digital Humanities, and part of that entails a strong and serious critique of work that fails to attend to these. This is published work, after all. And, while the repeated suggestion in each article, and in Tweets, that the method might help editors sort through masses of submissions might be an example of naive altruism; but it might also be a sign of something much loucher.
The real threat to the place of computing work in the Humanities is not, I don’t think, from the old-guard Luddite bogey man of current DH persecutionist fantasy, but from work like this, which presents statistical analysis as if it were literary analysis, with little care for what literary analysis has meant for those who have practised it thus far.
As a postscript, I want to make clear that I’m not at all against counting things in literary works or big corpora to inform analysis. I have even done it myself (here, here, here, and plenty elsewhere), in a much less sophisticated way than Dalvean does. But I’ve done it to investigate some feature of poetic diction, fully aware, even anxious, about the limitations of the method, and conscientiously sceptical about the inferences that can or should be drawn. The model is not the thing.
A PPS: something I would like Dalvean to compare would be contemporary poetry against other genres, including plain speech, to see if there is anything like a generic signal, or even a linguistic baseline. Such exploratory and provisional work might detect something of use for literary scholars with disposition towards algorithmic thinking, like me.
“I understand that there is a Ph.D. thesis somewhere that displays a list of Hardy’s novels in the order of the percentages of gloom they contain, but one does not feel that that sort of procedure should be encouraged.” —Northrop Frye, “The Function of Criticism At the Present Time” (1949)
On the contrary, such an analysis can be very interesting indeed: http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0083147#pone-0083147-g004
@Poetry Assessor – Thank you for commenting on this post – it is very much appreciated. Can you elaborate on what you find so interesting about the PLOS article?
What I find particularly interesting is that the sentiments encoded in texts mirror the feelings of the general population. Certainly, there is a lag; the greatest correlation between economic misery and “literary misery” is 10 years. However, there is a correlation, albeit small, even in the first year. Thus, even when not discussing economics specifically, the economic gloom seeps into the general culture. This in itself is an interesting observation.
When it comes to individual writers, the idea of mapping sentiments is likely to be of immense value. For example, the age-old idea that there is a link between certain mental states and artistic output could be explored by correlating sentiments in the novels over time with autobiographical data extracted from such sources as biographies, letters etc (I have actually begun such a project!).
The above are just two of the applications of mapping sentiments in text over time. There are also insights to be derived from the diachronic analysis of text complexity. No doubt you are aware of the research on the text analysis of novels and the early signs in the text of her later life dementia (‘Longitudinal detection of dementia through lexical and syntactic changes in writing: a case study of three British novelists http://llc.oxfordjournals.org/content/26/4/435.short).
In short, there are so many potential applications of analysing texts diachronically that I am very surprised Frye made the comment.
There is a version of this algorithm designed to analyse song lyrics – http://www.thelyricassessor.com.