You sometimes hear that Shakespeare contributed more words to the English language than anyone else. This claim is based on searches of the quotation evidence in the 2nd edition of the OED. In OED2, Shakespeare is the most-cited single-author source [33,131 quotations], and the most first-cited source in an entry [first evidence for 2,017 words], and the most first-cited source for new senses within an entry [first evidence for 5,527 numbered senses, though this includes the 2,017 above]. *[see note on data]
OED’s evidence quotations are what make it the great historical dictionary it is. First quotations, however, whether for a word or for a sense, are different from all the rest. That is because the only criterion for inclusion of first evidence is that it be, as far as the lexicographer can tell, the earliest recorded use (in print) of that word or sense.
For subsequent quotations, a whole raft of considerations come into play. How well the quotation illustrates the sense may be the most important of these, but lexicographers are also interested in showing historical range (choosing quotes from all the centuries in which it is in use), as well as a range of register (literary, journalistic, scientific usage, etc.). Other considerations that have been suggested include the intrinsic interest of the quotation, and the availability of the source to the general reader.
So in some ways, or for some purposes, it’s the make up of subsequent quotations that are the more interesting. No interface with OED has ever allowed one to isolate subsequent quotes (the 3rd quote in a sense, e.g.), so I wrote up a script to track the top-ten cited sources at each rank, for words (=lemmas) and for (numbered) senses. I’ve got some graphs of this below. First though, let’s note a few characteristics that flow from the fact of subsequentness:
- All words/senses have first quotations, but not all have subsequent ones. The longer a word/sense has been or was in use, the more quotations it will have.
- So, the more subsequent the rank, the fewer words/senses will have a quotation in that rank.
- Rare words and certain types of lexis (scientific, e.g.) typically contain many fewer quotations than the average for a word of the same lifespan.
- Within a sense section, quotations are distributed in ranks in chronological order.
- Consequently, overall, the rank of the quotation will track the date of the source. That is, there are relatively more quotations from the 13thC in 1st and 2nd position than in 6th or 7th. For the same reason, you are less likely to find a 20thC quotation in 1st position.
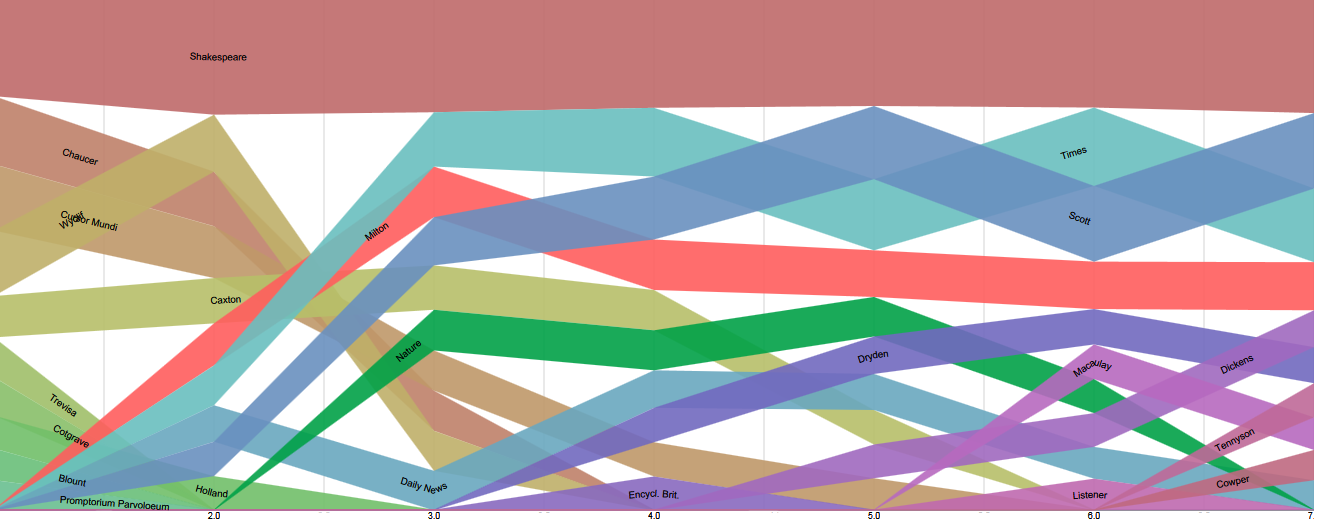
Okay, now for the charts. I’m working on a better visualization, but for now these will do, with a little explanation: These are “bump charts”, so for each ordinal rank on the x axis (1,2,3…7) you have a stack going from the most-cited source in that rank at the top, to the 10th most-cited at the bottom. The sources are tracked from one rank to the next.
For instance, in the first chart, you can see that the most-cited source in 3rd position in an entry is Shakespeare, followed by The Times and Nature. In 4th position, the order is Times, Shakespeare, Walter Scott, etc.. The thickness of the line at the ordinal represents the number of quotations or, in the case of the normalized charts (1.2 and 2.2), the percentage of the total number of quotes represented by the top ten sources, which allows one to compare, e.g., the make-up of all 6th quotes to all 2nd quotes on the same basis.
For each, you should be able to see a large version by clicking on the image.
1.1 Top 10 sources for 1st to 7th evidence citation for a word

1.2 Top 10 sources for 1st to 7th evidence citation in a word, by %age

2.1 Top 10 sources for 1st to 7th evidence in a numbered sense

{kind=link}
2.2 Top 10 sources for 1st to 7th evidence in a numbered sense, by %age

{kind=link}
I don’t want to go into too much discussion of the individual graphs here, except to point a few things that grabbed my attention. When looking at visualizations of data, generally we’re hoping to find things that don’t look like the general rule. So, just a few observations:
- Shakespeare rules all these graphs. Although the raw number of Shakespeare quotes diminishes as we go down rank, the percentage stays roughly the same, around 20% for senses and 13% for words. Although The Times surpasses Shakespeare at the word level at rank 4,5, and 6, this has more to do with the rise of The Times as a source, rather than a major decline in Shakespeare’s representation. At the sense level, The Times never really comes close to Shakespeare. This is significant because of chronology: we should expect Shakespearean representation to diminish at later ranks, but it doesn’t. Clearly some other factor is making up ground. Behold, the hand of the lexicographer!
- Milton is weird. Milton is the 7th most cited source (4th most cited individual author) in OED2, but he doesn’t crack the top 10 for first word evidence or first sense evidence. Yet, despite this, at the sense level he is the 6th most quoted source in the 2nd rank, the 3rd most quoted in the 3rd, and 4th in ranks 4-7. Why are there so few first citations by Milton, comparatively?
- Generic Flux. The overall picture shows a rise in newspapers, reference works, and scientific periodicals, and a decline in literary works, as we work down the ranks. This is to be expected, given the when these genres developed. Note, however, that this holds much more at the word level than at the sense level. I would expect to see this if I were plotting first citations against date of citation, since a periodical like Nature is probably more likely to record a new scientific word for the first time, than it is to record a new scientific sense of a word (that is, science tends more strongly to neologism vs lexical extension). But we’re not looking at time, exactly on the X axis. We’re looking at lexical continuity, and it’s odd to see Nature maintaining rank at the word level past 3rd position.
*[note on data: These are rough-ish numbers, based on the 1989 OED2. I’ve only counted quotes marked “Shaks.” here – though there a couple hundred by Shakespeare under other abbreviations. OED3 has a list of sources that currently has these metrics pegged at 33,126; 1,564; and 7,881, respectively, though I’m not sure whether their sense of “sense” includes small-letter senses (a, b, c…). If so, the comparable measure in my data would be 8,477, which makes a lot more sense…]
No Comments